muduo网络库解析
muduo采用了基于OOP 思想,Reactor 方式,one loop peer thead 的模式,驱动的事件回调的 epoll + 线程池面向对象,通过多线程和事件循环机制实现 高并发处理。
服务器流程TcpServer类:
包含主EventLoop,Acceptor,以及包含EventLoop的线程池。通过调用tcpServer的Start方法后,会初始化线程池,并开启线程中的EventLoop的监听。然后启动Acceptor监听socket端的新的连接服务的读事件。
若是多线程模式,主EventLoop负责监听Acceptor的读写时间,也就是服务器socket端的新的连接服务的读事件。若有新连接来,则通过Acceptor执行绑定的tcpServer的newConnection回调函数。newConnection回调函数会将新来的连接封装为Tcpconnection,并通过轮询算法为其分配对应的线程(EventLoop)。Tcpconnection中设置对应的回调函数,如果有相应的回调产生就会调用该回调函数(由用户设置),并提供Send()发送消息的接口供用户使用。每当新连接到来时,Tcpconnection封装完成会调用TcpConnection::connectEstablished函数,该函数通过启用Channel的读事件,并且通过tie函数设置Channel对应的weak_ptr智能指针,通过Epoller监听该Channel的读事件发生。
若新连接的事件发生,EventLoop会通过Poller监听到对应的Channel发生了事件,则会通过EventLoop中执行channel的handleEvent事件,对应的读写事件(该事件是用户在TcpServer中设置)。
主要类:
Channel:
保存fd,已经相应的回调函数。当Poller中有事件相应,则通过EventLoop执行该相应事件的回调。
EPollPoller:
使用epoll接口实现,用于fd事件的增删改,并用poll得到响应的Channel。
EventLoop:
一个线程一个EventLoop,一个EventLoop包含一个EPollPoller,以及注册的Channel。一旦EPollPoller返回响应的Channel。则执行Channel对应的回调函数。除此之外,EventLoop还保存有回调函数数组,通过EventFd唤醒EventLoop,并在一次循环中执行这些回调函数。
EventLoopThread:
一个绑定了EventLoop的线程,初始化时生成EventLoop,调用StartLoop时候则开启对应的EventLoop的监听。
EventLoopThreadPool:
一个线程池,保存有对应的线程以及对应的EventLoop,通过初始化线程数量开辟对应的线程,并启动所有的EventLoop的循环监听。
Acceptor:
服务器端的socket,包含EventLoop,用于监听新的连接。每当有新连接来时候,执行TcpServer中的newConnection回调。
TcpConnection:
封装一个连接,Tcpconnection中设置对应的回调函数,如果有相应的回调产生就会调用该回调函数(由用户设置),并提供Send()发送消息的接口供用户使用。每当新连接到来时,Tcpconnection封装完成会调用TcpConnection::connectEstablished函数。
TcpServer:
主类,提供设置回调函数接口,线程接口,需要主动传入主EventLoop已经服务器地址。通过start开启线程中的EventLoop的监听。然后启动Acceptor监听socket端的新的连接服务的读事件。如果有新连接则调用connectEstablished函数,分配EventLoop建立新的Tcpconnection。
网络通信模块
网络通信模块采用的是 muduo 网络库,本项目通过使用 C++11 简化 muduo 网络库,同时去除了 Boost 库的依赖以及一些冗余的组件,提取出 muduo 库中的核心思想,即 One Loop Per Thread。
1. Reactor
该网络库采用的是 Reactor 事件处理模式。在《Linux高性能服务器编程》中,对于 Reactor 模型的描述如下:主线程(即 I/O 处理单元)只负责监听文件描述符上是否有事件发生,有的话就立即将该事件通知工作线程(即逻辑单元)。此外,主线程不做任何其他实质性的工作。读写数据、接受新的连接,以及处理客户请求均在工作线程中完成。Reactor 模式的时序图如下:

而 muduo 网络库的时序图则如下图所示:

其次,在《Linux高性能服务器编程》一书中还提到了半同步/半异步的并发模式,注意,此处的“异步”与 I/O 模型中的异步并不相同,I/O 模型中的“同步”和“异步”的区分是内核应用程序通知的是何种事件(就绪事件还是完成事件),以及由谁来完成 I/O 读写(是应用程序还是内核)。而在并发模式中,“同步”指的是完全按照代码序列的顺序执行,“异步”则指的是程序的执行需要由系统事件来驱动,比如常见的系统终端、信号等。
而 muduo 库所采用的便是高效的半同步/半异步模式,其结构如下图所示:

上图中,主线程只管理监听 socket,连接 socket 由工作线程来管理。当有新的连接到来时,主线程就接受并将新返回的连接 socket 派发给某个工作线程,此后在该 socket 上的任何 I/O 操作都由被选中的工作线程来处理,直到客户关闭连接。主线程向工作线程派发 socket 的最简单的方式,是往它和工作线程之间的管道写数据。工作线程检测到管道上有数据可读时,就分析是否是一个新的客户连接请求到来。如果是,则把新 socket 上的读写事件注册到自己的 epoll 内核事件表中。上图中的每个线程都维持自己的事件循环,它们各自独立的监听不同的事件。因此,在这种高效的半同步/半异步模式中,每个线程都工作在异步模式,所以它并非严格意义上的半同步/半异步模式。
通常情况下,Reactor 模式的实现有如三几种方式:
- Single Reactor - Single Thread
- Single Reactor - Multi Threads
- Multi Reactors - Multi Threads
对于 “Single Reactor - Single Thread” 模型而言,其通常只有一个 epoll 对象,所有的接收客户端连接、客户端读取、客户端写入操作都包含在一个线程内,如下图所示:

但在目前的单线程 Reactor 模式中,不仅 I/O 操作在该 Reactor 线程上,连非 I/O 的业务操作也在该线程上进行处理了,这可能会大大延迟 I/O 请求的响应。为了提高服务器的性能,我们需要将非 I/O 的业务逻辑操作从 Reactor 线程中移动到工作线程中进行处理。
为此,可以通过使用线程池模型的方法来改进,即 “Single Reactor - Multi Threads” 模型,其结构如下图所示。将读写的业务逻辑交给具体的线程池来实现,这样可以显示 reactor 线程对 IO 的响应,以此提升系统性能。

尽管现在已经将所有的非 I/O 操作交给了线程池来处理,但是所有的 I/O 操作依然由 Reactor 单线程执行,在高负载、高并发或大数据量的应用场景,依然较容易成为瓶颈。
为了继续提升服务器的性能,进而改造出了如下图所示的 “Multi Reactors - Multi Threads” 模型:

在这种模型中,主要分为两个部分:mainReactor、subReactors。 mainReactor 主要负责接收客户端的连接,然后将建立的客户端连接通过负载均衡的方式分发给 subReactors,subReactors 则负责具体的每个连接的读写,而对于非 IO 的操作,依然交给工作线程池去做,对逻辑进行解耦。
而在 muduo 网络库中,便采用的是此种模型,每一个 Reactor 都是一个 EventLoop 对象,而每一个 EventLoop 则和一个线程唯一绑定,这也就是 One Loop Per Thread 的含义所在。其中,MainLoop 只负责新连接的建立,连接建立成功后则将其打包为 TcpConnection 对象分发给 SubLoop,在 muduo 网络库中,采用的是 “轮询算法” 来选择处理客户端连接的 SubLoop。之后,这个已建立连接的任何操作都交付给该 SubLoop 来处理。
通常在服务器模型中,我们可以使用 “任务队列” 的方式向 SubLoop 派发任务,即 MainLoop 将需要执行的任务放到任务队列中,而 SubLoop 则从任务队列中取出任务并执行,当任务队列中没有任务时,SubLoop 则进行休眠直到任务队列中有任务出现。但是在 muduo 网络库却中并未采用这一方式,而是采用了另一个更加高效的方式,以便让 MainLoop 唤醒 SubLoop 处理任务。
在上述的 “半同步/半异步” 模式中,我们提到了,主线程向工作线程派发 socket 最简单的方式,就是往它和工作线程之间的管道写数据。为此,我们可以在 MainLoop 和 SubLoop 之间建立管道来进行通信,当有任务需要执行时,MainLoop 通过管道将数据发送给 SubLoop,SubLoop 则通过 epoll 模型监听到了管道上所发生的可读(EPOLLIN)事件,然后调用相应的读事件回调函数来处理任务。
但是在 muduo 库中,则采用了更为高效的 eventfd() 接口,它通过创建一个文件描述符用于事件通知,自 Linux 2.6.22 以后开始支持。
eventfd 在信号通知的场景下,相对比 pipe 有非常大的资源和性能优势,它们的对比如下:
- 首先在于它们所打开的文件数量的差异,由于 pipe 是半双工的传统 IPC 实现方式,所以两个线程通信需要两个 pipe 文件描述符,而用 eventfd 则只需要打开一个文件描述符。总所周知,文件描述符是系统中非常宝贵的资源,Linux 的默认值只有 1024 个,其次,pipe 只能在两个进程/线程间使用,面向连接,使用之前就需要创建好两个 pipe ,而 eventfd 是广播式的通知,可以多对多。
- 另一方面则是内存使用的差别,eventfd 是一个计数器,内核维护的成本非常低,大概是自旋锁+唤醒队列的大小,8 个字节的传输成本也微乎其微,而 pipe 则完全不同,一来一回的数据在用户空间和内核空间有多达 4 次的复制,而且最糟糕的是,内核要为每个 pipe 分配最少 4K 的虚拟内存页,哪怕传送的数据长度为 0。
2. I/O multiplexing
在 Linux 系统下,常见的 I/O 复用机制有三种:select、poll 和 epoll。
其中,select 模型的缺点如下:
- 单个进程能够监视的文件描述符的数量存在最大限制,通常是 1024,当然可以更改数量,但由于 select 采用轮询的方式扫描文件描述符,文件描述符数量越多,性能越差;
- 内核和用户空间的内存拷贝问题,select 需要复制大量的句柄数据结构,会产生巨大的开销;
- select 返回的是含有整个句柄的数组,应用程序需要遍历整个数组才能发现哪些句柄发生了事件;
- select 的触发方式是水平触发,应用程序如果没有对一个已经就绪的文件描述符进行相应的 I/O 操作,那么之后每次 select 调用还是会将这些文件描述符通知进程;
相比于 select 模型,poll 则使用链表来保存文件描述符,因此没有了监视文件数量的限制,但其他三个缺点依然存在。
而 epoll 的实现机制与 select/poll 机制完全不同,它们的缺点在 epoll 模型上不复存在。其高效的原因有以下两点:
- 它通过使用红黑树这种数据结构来存储 epoll 所监听的套接字。当添加或者删除一个套接字时(epoll_ctl),都是在红黑树上进行处理,由于红黑树本身插入和删除性能比较好,时间复杂度为 O(logN),因此其效率要高于 select/poll。
- 当把事件添加进来的时候时候会完成关键的一步,那就是该事件会与相应的设备(网卡)驱动程序建立回调关系,当相应的事件发生后,就会调用这个回调函数。这个回调函数其实就是把该事件添加到
rdllist这个双向链表中。那么当我们调用 epoll_wait 时,epoll_wait 只需要检查 rdlist 双向链表中是否有存在注册的事件,效率非常可观。
epoll 对文件描述符的操作有两种模式:LT(Level Trigger,电平触发)和 ET(Edge Trigger,边沿触发)模式。其中,LT 模式是默认的工作模式,这种模式下 epoll 相当于一个效率较高的 poll。当往 epoll 内核事件表中注册一个文件描述符上的 EPOLLOUT 事件时,epoll 将以 ET 模式来操作该文件描述符。ET 模式是 epoll 的高效工作模式。
对于采用 LT 工作模式的文件描述符,当 epoll_wait 检测到其上有事件发生并将此事件通知应用程序后,应用程序可以不立即处理该事件。这样,当应用程序下一次调用 epoll_wait 时,epoll_wait 还会再次向应用程序通告此事件,直到该事件被处理。而对于采用 ET 工作模式的文件描述符,当 epoll_wait 检测到其上有事件发生并将此事件通知应用程序后,应用程序必须立即处理该事件,因为后续的 epoll_wait 调用将不再向应用程序通知这一事件。可见,ET 模式在很大程度上降低了同一个 epoll 事件被重复触发的此时,因此效率要比 LT 模式高。
在 muduo 网络库中,则采用了 LT 工作模式,其原因如下:
- 不会丢失数据或者消息,应用没有读取完数据,内核是会不断上报的;
- 每次读数据只需要一次系统调用;照顾了多个连接的公平性,不会因为某个连接上的数据量过大而影响其他连接处理消息;
在 muduo 网络库中,借助于 Linux 下“一切皆文件”的思想,通过 epoll 进行管理的主要有如下三个类型的事件:
- 网络 I/O 事件:通过套接字(socket)文件描述符进行管理;
- 线程通知事件:通过 eventfd 唤醒 SubLoop 处理相应的任务;
- 定时器事件:通过 timerfd 来处理定时器事件;
3. QPS
QPS(Query Per Second) 即每秒查询率,QPS 是对一个特定的查询服务器在规定时间内所处理流量多少的衡量标准。
muduo 网络库核心功能及其设计思想
采自 https://zhuanlan.zhihu.com/p/636581210
参考 :https://blog.csdn.net/T_Solotov/article/details/124044175
长文梳理Muduo库核心代码及优秀编程细节剖析陈硕muduo库我在地铁站里吃闸机的博客-CSDN博客
零、写在前面
本文所涉及的 muduo 源码以最新版本(2022.11.01 提交)为例,/examples/simple/echo下是 muduo 提供的回声服务器的源码。一个简单的 echo server 的主函数如下,其中 EchoServer 中包含一个 TcpServer 对象,并在构造函数中绑定了 onConnection 和 onMessage 回调。
// code 1
int main() {
LOG_INFO << "pid = " << getpid();
muduo::net::EventLoop loop;
muduo::net::InetAddress listenAddr(2007);
EchoServer server(&loop, listenAddr);
server.start();
loop.loop();
}
那么 muduo 的核心源码(这里不包括 http、protorpc 等模块)可以分为三类:
1)以 EventLoop 为中心的 Reactor 网络模型的实现,包含 EventLoop、Poller、Channel 等。
2)以 TcpServer 为中心的上层组件,包含 TcpServer、TcpConnection、Acceptor、Buffer 等。
3)Thread、InetAddress、Socket 等类实现对 Linux 系统底层功能的封装。(本文不进行分析)
一、Reactor 网络模型的实现
muduo 实现的其实是一个多 Reactor 多线程模型,经典的模型图如下 [4],出处已不可考。单个 Reactor 的实现涉及 EventLoop、Poller、Channel三个类,多 Reactor 多线程又添加了两个类,即 EventLoopThread、EventLoopThreadPool ,下面先完成单个 Reactor 模型的分析。
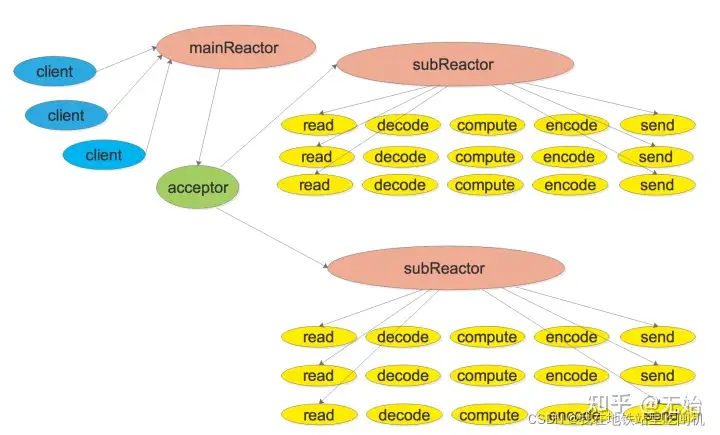
多 Reactor 多线程模型示意图
1.1 单 Reactor 模型的实现
EventLoop 是一个事件循环,核心功能就在 loop() 成员函数中,我们追踪 code 1 line 8 如下。在 while 循环中,poller_->poll() 等待事件到来或者超时,所有活跃的 fd 会保存在 activeChannels_中,之后遍历该数组,调用绑定的回调函数来处理事件,最后处理 doPendingFunctors()(这是 queueInLoop() 为其添加的)。
// code 2
void EventLoop::loop() {
...
while (!quit_)
{
activeChannels_.clear();
pollReturnTime_ = poller_->poll(kPollTimeMs, &activeChannels_);
...
for (Channel* channel : activeChannels_) {
currentActiveChannel_ = channel;
currentActiveChannel_->handleEvent(pollReturnTime_);
}
...
doPendingFunctors();
}
...
}
在这之中涉及了另外两个类,一个是 Poller,另一个是 Channel。一个一个分析,首先看 Poller。
Poller 在 muduo 中被设计成了抽象类,可以派生出 PollPoller 和 EPollPoller 两个派生类,底层分别调用 poll 和 epoll 进行多路复用。本文后面提到的 Poller 是 Poller 和 EPollPoller 的结合体。Poller 的核心功能函数就是 poll(),我们追踪 code 2 line 7 如下。在 poll() 里阻塞等待在 epoll_wait 上,然后通过 fillActiveChannels() 将所有已经激活的 fd 保存在 activeChannels 里,在 fillActiveChannels() 里会设置 revents。注意 epoll_wait 返回的原因有多种,监听时间超时、注册的 fd 上有事件到来、定时器事件超时、或者其他线程添加了任务触发了 eventfd。
//code 3
Timestamp EPollPoller::poll(int timeoutMs, ChannelList* activeChannels) {
...
int numEvents = ::epoll_wait(epollfd_,
&*events_.begin(),
static_cast<int>(events_.size()),
timeoutMs);
...
if (numEvents > 0) {
...
fillActiveChannels(numEvents, activeChannels);
...
}
...
return now;
}
另一个类是 Channel,封装了一个 fd(muduo 使用了统一事件源,可以是 socket fd,timerfd,eventfd,signalfd),fd 上关心的事件 events,实际发生的事件 revents(对应 fillActiveChannels() 中修改的内容),还有各个事件对应的回调函数。Channel 中重要的功能就是 handleEvent() 了,会根据发生的事件执行对应的回调函数,没什么好说的。但是具体在实现的时候还是有技巧和关键点的,如智能指针的观察模式,这个在后面的部分会提到。
最后有几点需要注意的地方,一个需要注意的地方是三个组件的交互。EventLoop 是持有另外两个组件的,其中Channel 是直接持有,EventLoop 会负责其生命周期;Poller是通过 uniqueptr 间接持有,其生命周期与 EventLoop 相同。Channel 不能直接调用 Poller ,而是通过 EventLoop进行间接调用。即 Channel::update() 到 `loop->updateChannel(this)到poller_->updateChannel(channel)`,通过这个调用链完成 epoll 上 fd 的注册和修改。一个非常重要的调用链的例子如下:
// code 4
void Acceptor::listen() {
loop_->assertInLoopThread();
listening_ = true;
acceptSocket_.listen();
acceptChannel_.enableReading();
}
code 4 line 5 调用了 ::listen() 系统调用,等到新的连接请求到达之后,通过 line 6 向 acceptChannel_添加对于读事件的关注,而后通过上面的调用链向 epoll 上注册该事件,见 code 5。
// code 5
// Channel.h
void enableReading() { events_ |= kReadEvent; update(); }
// Channel.cc
void Channel::update() {
...
loop_->updateChannel(this);
}
// EventLoop.cc
void EventLoop::updateChannel(Channel* channel)
{
...
poller_->updateChannel(channel);
}
// EPollPoller.cc
void EPollPoller::updateChannel(Channel* channel)
{
// 通过 epoll_ctl 执行具体的修改操作
}
另外一个需要注意的地方是 Channel 和 Poller 都是只属于一个 EventLoop 的,只会在自己的 IO 循环中被调用,所以成员都无需加锁。但是在后面的多 Reactor 时情况就会变复杂,所以 EventLoop 通过 runInLoop() 进行了保证,用户的回调一定会在自己的 IO 线程执行,如果是自己的 IO 循环,直接执行回调,否则调用 queueInLoop() 添加到自己的的 IO 线程的 pendingFunctors_ 中(这里就需要加锁了,因为跨线程),通过事件循环最后的 doPendingFunctors() (code 2 line 14)执行。
// code 6
void EventLoop::runInLoop(Functor cb) {
if (isInLoopThread()) {
cb();
}
else {
queueInLoop(std::move(cb));
}
}
最后还有一个小地方,EventLoop 要保证一个线程中至多只存在一个实例,是通过线程局部变量实现的,muduo 使用了 __thread,C++11 还提供了 thread_local。另外 EventLoop 还包含一个 pid,isInLoopThread() 就是通过这个来判断当前线程是不是自己的 IO 线程。
关于单个 Reactor 模型的介绍就到这里,Channel、Poller、EventLoop 三者共同作用组成了 Reactor,其中 Channel 封装了 fd 、fd 上关注的事件、fd 上实际发生的事件、每种事件对应的回调,Poller 封装了和事件监听有关的方法和成员,主要就是 epoll 系列系统调用,调用一次 poll() 就可以有一次的监听结果,然后处理活跃的 fd 上发生的事件。作为一个网络服务器,需要有持续监听、持续获取监听结果、持续处理监听结果对应的事件的能力,这就是 EventLoop 的作用了。
1.2 多 Reactor 模型的实现
在本节的开始,先介绍一个比较独立的组件 TimerQueue,该组件还依赖于 Timer 和 TimerId 两个类,这是 muduo 中与定时器有关的类。一个好的服务器程序应该可以处理 IO 事件、定时事件和信号事件 [游双]。其中 IO 事件前面已经提到了,信号事件过于复杂,而且 Linux 信号与多线程水火不容,[2] 中指出多线程程序中,使用 signal 的第一原则就是不要使用 signal,muduo 中的处理是使用了统一事件源 signalfd 直接将信号转换为文件描述符去处理(大概是,没有仔细研究这一部分)。对于定时事件的处理,也存在两个思路,一种是在事件循环之前查找最近一个要超时的定时器的超时时间,将该时间作为 epoll 的超时时间,在 epoll_wait 返回之后,先处理已经超时的定时器,然后再处理 IO 事件。第二种思路,也是 muduo 的思路,使用 Linux 中提供的 timerfd,用处理 IO 事件的方式来处理定时事件,保证一致性。所以在 muduo 中,三类事件用文件描述符进行了统一,在 Channel 类的开始也有注释。
///
/// A selectable I/O channel.
///
/// This class doesn't own the file descriptor.
/// The file descriptor could be a socket,
/// an eventfd, a timerfd, or a signalfd
class Channel : noncopyable {
...
}
实现定时器需要关注的另一个问题就是定时器的组织方式,常见的有链表、时间轮、时间堆。muduo 使用了二叉搜索树,即typedef std::set<Entry> TimerList;,其底层是红黑树。关于定时器各种组织方式的区别和 muduo 选择二叉搜索树的理由可以参考 [游双] 和 [2],本人研究不多,不再展开。
下面正式开始对于多 Reactor 模型的介绍,涉及的类就是 EventLoopThread、EventLoopThreadPool。
one loop pre thread 是 [2] 中频繁提到的设计思想,其主旨就是一个 IO 事件循环和一个线程绑定,一个线程中只能有一个 IO 循环,一个 IO 循环中的事件只能被该线程管理,事件的回调也只能在该线程中执行。具体落实在 muduo 上,就是 EventLoop 和 Thread 一一对应,也就是 EventLoopThread。EventLoopThread 的核心功能就是通过 startLoop() 启动线程,开启 IO 循环。其中最重要的是需要通过条件变量等待 EventLoop 创建成功并开启 loop(),见 code 7 line 10 和 line 28。
// code 7
EventLoop* EventLoopThread::startLoop() {
assert(!thread_.started());
thread_.start();
EventLoop* loop = NULL;
{
MutexLockGuard lock(mutex_);
while (loop_ == NULL) {
cond_.wait();
}
loop = loop_;
}
return loop;
}
void EventLoopThread::threadFunc() {
EventLoop loop;
if (callback_) {
callback_(&loop);
}
{
MutexLockGuard lock(mutex_);
loop_ = &loop;
cond_.notify();
}
loop.loop();
//assert(exiting_);
MutexLockGuard lock(mutex_);
loop_ = NULL;
}
至此单个线程的 one loop pre thread 就完成了,下面就要拓展到多线程 EventLoopThreadPool。在 code 1 line 7 中,echo server 通过 server.start();启动服务器,有两个步骤,一是启动 EventLoopThreadPool,二是开始监听新连接的到达。
// code 8
void TcpServer::start() {
if (started_.getAndSet(1) == 0) {
threadPool_->start(threadInitCallback_);
assert(!acceptor_->listening());
loop_->runInLoop(
std::bind(&Acceptor::listen, get_pointer(acceptor_)));
}
}
threadPool_->start();中创建了 numThreads_ 个 EventLoopThread作为子线程。这里有两个重要的概念:baseLoop(mainLoop、mainReactor)和 subLoop(subReactor),见最开始的多 Reactor 多线程模型图。最为特殊的,如果 numThreads_ 为 0,那么就没有创建子线程,那么接收新连接和连接间的通信就都会在 baseLoop 中被处理,这个在后面会提到。
多 Reactor 模型有两个需要关注的地方,为一个新的连接分为一个 IO Loop,该连接上的发生的所有事件都要在该 IO Loop 中被处理。分配连接的逻辑在 Tcp 系列组件分析的时候进行讲述,连接上发生的事件都要在自己所属的线程中进行处理其实在 1.1 单 Reactor 模型分析中已经提到了,现在放在多 Reactor 情景下再强调一下。
通过 __thread保证线程中至多只存在一个 EventLoop,通过 pid 来标识当前 EventLoop 所属的线程,如果当前线程就是 IO loop 所属的线程,那么就可以直接执行回调,否则就调用 queueInLoop 将回调添加到自己的 pendingFunctors_中,然后唤醒自己的线程。
// code 9
void EventLoop::queueInLoop(Functor cb) {
{
MutexLockGuard lock(mutex_);
pendingFunctors_.push_back(std::move(cb));
}
if (!isInLoopThread() || callingPendingFunctors_) {
wakeup();
}
}
当一个 IO Loop 有了需要自己处理的回调时,如何被唤醒也是网络编程中的一个要点,常用的技术有两个,一个是通过 socketpair() 系统调用创建一对可全双工通信的系统调用,或是使用 eventfd 作为统一事件源,当然两者都需要添加到 epoll 中进行监听。muduo 使用了第二种,向 Poller中注册 wakeupChannel_ 并监听读事件的逻辑在 EventLoop 中完成,这里就不再展示。当需要唤醒一个 EventLoop 时,就向它的 eventfd 中写入一个字符即可,该 EventLoop就会从 epoll_wait 退出。唤醒的语句是 code 9 line 8,退出的语句是 code 2 line 7,之后就可以在 code 2 line 14 中处理唤醒前添加的回调函数了。
doPendingFunctors() 这里还有个小技巧,因为需要执行的回调可能会很多,依次同步的调用所有回调会比较耗时,并且在执行回调时会阻塞其他线程向本线程添加新的回调任务,使用 swap 技巧将 pendingFunctors_进行备份,可以很好的缩短临界区的长度,避免阻塞。另一方面也避免了死锁,因为回调函数也可能再次调用 queueInLoop()。
// code 10
void EventLoop::doPendingFunctors() {
std::vector<Functor> functors;
callingPendingFunctors_ = true;
{
MutexLockGuard lock(mutex_);
functors.swap(pendingFunctors_);
}
for (const Functor& functor : functors) {
functor();
}
callingPendingFunctors_ = false;
}
至此与 Reactor 有关的组件就分析完成了。
二、TcpServer 系列组件的分析
在 muduo 中或者说网络通信中,一共存在两类 fd,一类是 listen fd,在 muduo 中对应 acceptChannel_,封装在 Acceptor 里,另一类是 connection fd,对应的抽象就是 TcpConnection。这在 TcpServer 里都有体现,即 acceptor_ 和 connections_。[4] 中有一段总结性的文字:TcpConnection类和 Acceptor 类是兄弟关系,Acceptor 用于 baseLoop 中,对 listen fd 及其相关方法进行封装(监听新连接到达、接受新连接、分发连接给 subLoop 等),TcpConnection 用于 subLoop 中,对 connection fd 及其相关方法进行封装(读消息事件、发消息事件、连接关闭事件、错误事件等)。
那么首先,Acceptor 是对于 listen fd 的封装,主要的数据成员就是 acceptSocket_ 和 acceptChannel_,以及一个 handleRead()回调函数,在 listen fd 读事件到达时被回调(listen fd 只关心读事件)。Acceptor 核心的功能在 listen() 成员函数里,主要就是调用 ::listen() 系统调用,然后将该 listen fd 通过上面提到的调用链注册到 epoll 上(已经在 1.1 中进行了分析)。等到读事件到来之后,就会调用绑定好的 Acceptor::handleRead() 函数,接收新连接,然后执行 TcpServer::newConnection 创建新的 TcpConnection。
简单了解完 Acceptor 的实现,现在直接转到最上层的 TcpServer,TcpServer 的核心在 start() 上(code 8),但是在此之前还有一个构造函数。在构造函数中用户传入了一个 EventLoop作为 baseLoop 或者说 mainLoop,创建了一个 Acceptor,新的连接请求会运行在 baseLoop 上,创建了一个 EventLoopThreadPool,所有的 IO 请求会分配到各个 subLoop 上,通过轮询的方式。但是如果没有 subLoop,即 threadNums_ 为 0,新的连接请求和 IO 请求都是在 baseL oop 上处理的。最后在函数体里为 Acceptor 设置新连接到来时的回调。
// code 11
TcpServer::TcpServer(EventLoop* loop,
const InetAddress& listenAddr,
const string& nameArg,
Option option)
: loop_(CHECK_NOTNULL(loop)),
ipPort_(listenAddr.toIpPort()),
name_(nameArg),
acceptor_(new Acceptor(loop, listenAddr, option == kReusePort)),
threadPool_(new EventLoopThreadPool(loop, name_)),
connectionCallback_(defaultConnectionCallback),
messageCallback_(defaultMessageCallback),
nextConnId_(1) {
acceptor_->setNewConnectionCallback(
std::bind(&TcpServer::newConnection, this, _1, _2));
}
上层应用中最后一个组件是 TcpConnection,TcpConnection 的类是最复杂的,承载着事件具体处理的处理逻辑交互,还有模糊的生命周期。[2] 中提到,TCP 网络编程最本质的是处理三个半事件:连接的建立,包括服务端接受新连接和客户端成功发起连接。连接的断开,包括主动断开和被动断开。消息到达,文件描述符可读。消息发送完毕,这算半个(但是不容易处理)。接下来我也会按照这个思路剖析 TcpConnection 的实现逻辑。
2.1 连接的建立
前面提到当有连接事件到来时,会回调 Acceptor::handleRead() 函数,接收新连接,然后执行 TcpServer 构造函数为 Acceptor 设置的 NewConnectionCallback,即 TcpServer::newConnection。
// code 12
void Acceptor::handleRead() {
...
int connfd = acceptSocket_.accept(&peerAddr);
if (connfd >= 0) {
...
if (newConnectionCallback_) {
newConnectionCallback_(connfd, peerAddr);
} else {
sockets::close(connfd);
}
}
...
}
void TcpServer::newConnection(int sockfd, const InetAddress& peerAddr) {
...
EventLoop* ioLoop = threadPool_->getNextLoop();
...
TcpConnectionPtr conn(new TcpConnection(ioLoop,
connName,
sockfd,
localAddr,
peerAddr));
connections_[connName] = conn;
conn->setConnectionCallback(connectionCallback_);
conn->setMessageCallback(messageCallback_);
conn->setWriteCompleteCallback(writeCompleteCallback_);
conn->setCloseCallback(
std::bind(&TcpServer::removeConnection, this, _1)); // FIXME: unsafe
ioLoop->runInLoop(std::bind(&TcpConnection::connectEstablished, conn));
}
首先就是 1.2 中提到的多 Reactor 模型的分配连接的逻辑,通过轮询算法为这个新连接选择一个它所属的 EventLoop,即一个 subLoop,如果 threadNums_ 为 0 的话,选出来的就是 baseLoop。一个连接永远属于一个 IO loop,这个 fd 永远属于一个 epoll,所以要保证该连接的回调要在自己的 IO 循环里被执行,这样就免去了加锁的开销,也避免了惊群问题,如何解决在第一部分已经提到。
之后就为这个新连接封装一个 TcpConnection,TcpConnection 里会包含一个 Channel(可以看出用户不会直接使用 Channel,而是使用其上层的封装),在 TcpConnection 的构造函数中会为自己的 Channel 设置各种回调,包括读、写、关闭、错误。也就是说 Channel 的各种回调实际上是 TcpConnection 提供的。
// code 13
TcpConnection::TcpConnection(EventLoop* loop,
const string& nameArg,
int sockfd,
const InetAddress& localAddr,
const InetAddress& peerAddr)
: loop_(CHECK_NOTNULL(loop)),
...
socket_(new Socket(sockfd)),
channel_(new Channel(loop, sockfd)),
... {
channel_->setReadCallback(
std::bind(&TcpConnection::handleRead, this, _1));
channel_->setWriteCallback(
std::bind(&TcpConnection::handleWrite, this));
channel_->setCloseCallback(
std::bind(&TcpConnection::handleClose, this));
channel_->setErrorCallback(
std::bind(&TcpConnection::handleError, this));
...
}
创建了TcpConnection 之后,再为其提供各种回调函数,包括连接建立和断开的、消息到来的、消息发送完成的、连接关闭的,其中前三个是用户提供的,即具体的业务逻辑,最后一个是 TcpServer 提供的,负责连接断开之后的清理。要注意这里出现了两套回调函数,不要搞混了,一套是 TcpConnection 为 Channel 设置的回调,是事件到来之后立刻被执行的(code 2 line 11),另一套可以看作是 TcpServer 为 TcpConnection 设置的,这些函数是在第一套回调函数执行的过程中被回调的,可以参考 2.2 消息到来的分析。另外 [4] 作者绘制的一副示意图明确了两套回调函数之间的关系以及在 TcpConnection 类中的关系,如下。
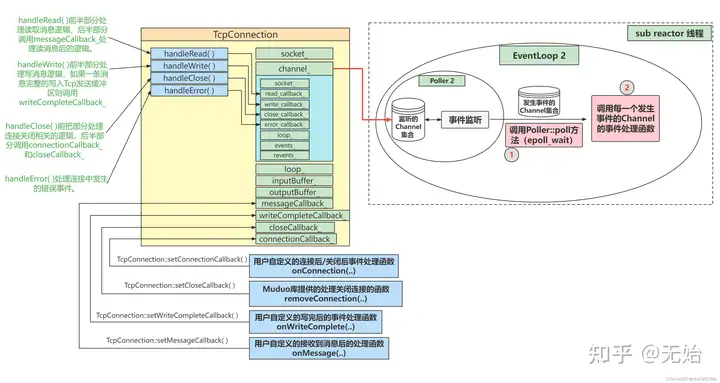
最后的最后执行了 TcpConnection::connectEstablished(),完成了连接的建立。这里就有个问题了,TcpServer::newConnection 设置给了 Acceptor 的 NewConnectionCallback,该函数是在 Acceptor::handleRead() 中被调用的,而 Acceptor 肯定是属于 baseLoop 的,然而 TcpConnection::connectEstablished() 的运行一定要是在该连接所在的线程,也就是 subLoop(ioLoop),ioLoop 不一定是 baseLoop,所以使用了 ioLoop->runInLoop()。
2.2 消息的到达
在连接建立的最后,TcpConnection::connectEstablished() 里启动了对于 connection fd 读事件的监听,当有消息到达时,通过 code 2 line 11 执行了绑定好的读事件回调,即 TcpConnection 为 Channel 提供的 TcpConnection::handleRead()。在其中进行了消息的读取,然后调用了 TcpServer (更准确的说是用户)为 TcpConnection 提供的消息到来时的回调 messageCallback_,进行业务逻辑的处理。对于 echo server 来说,就是原封不动的把消息再发回去(code 15 line 8)。
// code 13
void TcpConnection::connectEstablished() {
...
channel_->tie(shared_from_this());
channel_->enableReading();
connectionCallback_(shared_from_this());
}
void TcpConnection::handleRead(Timestamp receiveTime) {
loop_->assertInLoopThread();
int savedErrno = 0;
ssize_t n = inputBuffer_.readFd(channel_->fd(), &savedErrno);
if (n > 0) {
messageCallback_(shared_from_this(), &inputBuffer_, receiveTime);
} else if (n == 0) {
handleClose();
} else {
errno = savedErrno;
LOG_SYSERR << "TcpConnection::handleRead";
handleError();
}
}
有个小问题在这里提一下,Buffer 的 readFd() 返回本次读取数据的字节数,如果返回值为 -1,则说明发生了错误,而 muduo 只支持 LT 模式,所以读事件不会出现 EAGAIN 的错误,一旦出现错误,就要通过 handleError() 进行处理了 [4]。
2.3 连接的断开
当Buffer 的 readFd() 返回的本次读取数据的字节数为 0 时,就需要关闭连接了,调用了 TcpConnection::handleClose()。在里面调用了 closeCallback_,它是在创建 TcpConnection 时由 TcpServer 为其绑定的,closeCallback_ 调用到了 TcpServer::removeConnection,然后通过一系列的回调最终调用到了 TcpConnection::connectDestroyed,进行连接的清理。主要的工作就是关闭 Channel 上的所有事件,将 Channel 从 Poller 上移除,将 TcpConnection 从 TcpServer 的 connections_ 里移除。
// code 14
void TcpConnection::handleClose() {
...
channel_->disableAll();
TcpConnectionPtr guardThis(shared_from_this());
connectionCallback_(guardThis);
// must be the last line
closeCallback_(guardThis);
}
void TcpConnection::connectDestroyed() {
loop_->assertInLoopThread();
if (state_ == kConnected)
{
setState(kDisconnected);
channel_->disableAll();
connectionCallback_(shared_from_this());
}
channel_->remove();
}
除了被动关闭连接(客户端关闭连接,服务端在 handleRead 时返回 0,触发 handleClose),muduo 还提供了主动关闭连接的功能,即 TcpConnection::forceClose(),TcpConnection::forceCloseWithDelay(double seconds),TcpConnection::forceCloseInLoop()三个成员函数,分析到最后调用的也是 handleClose。服务端主动关闭连接不常见,muduo 最初的版本只提供了被动关闭连接的处理,参考 [2]。
2.4 消息的发送
上面三种情况,都是 TcpServer,或者说 EventLoop 被动的处理到来的事件,触发一系列的回调,但是还有一个主动的事件,也就是发送消息(不考虑主动断开连接)。比如在 echo server 里回复收到的消息,是通过 conn->send(msg) 实现的。
// code 15
void EchoServer::onMessage(const muduo::net::TcpConnectionPtr& conn,
muduo::net::Buffer* buf,
muduo::Timestamp time) {
muduo::string msg(buf->retrieveAllAsString());
LOG_INFO << conn->name() << " echo " << msg.size() << " bytes, "
<< "data received at " << time.toString();
conn->send(msg);
}
连接的断开比连接的创建要难,同样发送数据比接收数据更难。muduo 中提供了 send() 和 shutdown() 两类发送方式,send() 还提供了三种不同的重载函数,为了保证可以跨线程调用,还提供了 sendInLoop() 和 shutdownInLoop() 两个函数。本次的分析就以 echo server 的调用(code 15 line 8)为起点进行追踪。在开始之前,有两个重点提醒:muduo 采用了 LT 模式,所以我们只在必要时才会关注 fd 上的读事件,否则会造成 busy loop。send() 会尝试直接发送数据,发送不完会将剩余数据保存,然后启动 fd 上读事件的监听。
conn->send(msg) 语句进行了数据的发送,注意这时该 TcpConnection 上的 Channel 是没有关注读事件的。conn->send(msg)通过一系列的调用,最后会调用到 TcpConnection::sendInLoop(),对于该函数的分析,请参照注释。
// code 16
void TcpConnection::sendInLoop(const void* data, size_t len) {
loop_->assertInLoopThread();
ssize_t nwrote = 0; // 已经发送的字节数
size_t remaining = len; // 剩余需要发送的字节数
...
if (!channel_->isWriting() && outputBuffer_.readableBytes() == 0)
{
nwrote = sockets::write(channel_->fd(), data, len); // 进行一次发送
// 发送成功
if (nwrote >= 0) {
remaining = len - nwrote;
if (remaining == 0 && writeCompleteCallback_)
{
loop_->queueInLoop(std::bind(writeCompleteCallback_, shared_from_this()));
}
}
// 发送失败,处理错误,省略
...
}
assert(remaining <= len);
// write() 一次之后还有剩余
if (!faultError && remaining > 0)
{
size_t oldLen = outputBuffer_.readableBytes();
if (oldLen + remaining >= highWaterMark_
&& oldLen < highWaterMark_
&& highWaterMarkCallback_)
{
loop_->queueInLoop(std::bind(highWaterMarkCallback_, shared_from_this(), oldLen + remaining));
}
// 保存在 Buffer 里
outputBuffer_.append(static_cast<const char*>(data)+nwrote, remaining);
// 将该 Channel 上的读事件注册到 Poller
if (!channel_->isWriting())
{
channel_->enableWriting();
}
}
}
至于为什么不一直写直到发送完毕,还有 LT 和 ET 模式对于读写事件的性能影响,可以参考 [2] 中对应章节,这里不再展开。剩下还有一部分就是老生常谈的了,当写事件到达时,通过 code 2 line 11 执行了绑定好的写事件回调,即 TcpConnection 为 Channel 提供的 TcpConnection::handleWrite()。注意等到写完之后,需要立刻关闭该 Channel 上对于写事件的监听,避免 busy loop。
// code 17
void TcpConnection::handleWrite() {
loop_->assertInLoopThread();
if (channel_->isWriting()) {
ssize_t n = sockets::write(channel_->fd(),
outputBuffer_.peek(),
outputBuffer_.readableBytes());
if (n > 0) {
outputBuffer_.retrieve(n);
if (outputBuffer_.readableBytes() == 0) {
channel_->disableWriting();
if (writeCompleteCallback_) {
loop_->queueInLoop(std::bind(writeCompleteCallback_, shared_from_this()));
}
if (state_ == kDisconnecting) {
shutdownInLoop();
}
}
}
...
}
...
}
到这里对于 TcpServer、Acceptor、TcpConnection的介绍,还有组件之间的交互逻辑的分析就到一段落了,这部分还有一些边角没有提到,比如高水位回调和低水位回调,参考 [2] 的相关内容,这里不再介绍了。
三、两大组件的设计技巧
在第二部分中,对于 TcpConnection 的介绍,是围绕着网络事件的交互逻辑进行的,对于其生命周期的管理并没有提及,因为其生命周期非常复杂和模糊,比如它可以直接被用户所操作。另外在读写事件的回调中,频繁会出现 Buffer 对象,它作为一个缓冲区,是 muduo 中设计非常精妙的一个组件。本章节就会来分析这两个组件:TcpConnection 的生命周期管理,Buffer 的设计与实现。
3.1 TcpConnection 的生命周期
[2] 中提到,TcpConnection 是 muduo 里唯一默认使用 shared_ptr 来管理的类,也是唯一继承 enable_shared_from_this 的类(现在有了 http、rpc 模块,可能就不是了),原因就是 TcpConnection 有模糊的生命周期。当有一个新的连接请求到达后,Acceptor 的 handleRead 会调用 TcpServer 为其设置的 NewConnectionCallback,创建一个新连接,这就是 TcpConnection的诞生。
// code 18
typedef std::shared_ptr<TcpConnection> TcpConnectionPtr;
void TcpServer::newConnection(int sockfd, const InetAddress& peerAddr) {
...
TcpConnectionPtr conn(new TcpConnection(ioLoop,
connName,
sockfd,
localAddr,
peerAddr));
connections_[connName] = conn;
conn->setConnectionCallback(connectionCallback_);
conn->setMessageCallback(messageCallback_);
conn->setWriteCompleteCallback(writeCompleteCallback_);
conn->setCloseCallback(
std::bind(&TcpServer::removeConnection, this, _1)); // FIXME: unsafe
ioLoop->runInLoop(std::bind(&TcpConnection::connectEstablished, conn));
}
我试着分析一下该 TcpConnectionPtr 对象的引用计数,不一定正确。代码在堆上分配了一个 TcpConnection 对象,由 conn 来持有,该对象会在退出作用域时析构,但是在代码中还存在两次拷贝,一次是 code 18 line 11,另外一次是 line 17。connections_ 中保存的智能指针会一直存在直到被销毁(后面看销毁的过程)。line 17 的 std::bind 会拷贝一份实参,导致 TcpConnectionPtr 的生命周期延长 [2],这是一个临时的 std::function 对象,那么等到函数执行完,实参就会被销毁。
进入 connectEstablished() 看一下,代码中出现了两次 sharedfrom_this(),但是 tie() 和 `connectionCallback()` 的参数都是 const to reference,不会增加引用计数。
// code 19
void TcpConnection::connectEstablished() {
loop_->assertInLoopThread();
assert(state_ == kConnecting);
setState(kConnected);
channel_->tie(shared_from_this());
channel_->enableReading();
connectionCallback_(shared_from_this());
}
等到连接建立的过程结束,TcpConnection 的智能指针,引用计数为 1,位于 TcpServer 的 connections_ 中。
所以为什么要使用智能指针呢,上面的过程使用裸指针一样可以完成,[4] 中提到使用裸指针最重要的原因是避免悬空指针,因为 TcpConnection 会和用户直接交互,而我们的网络库不能假定用户的行为。如果使用裸指针,用户 delete 之后,程序中其他用到该指针的位置都会报错,而如果使用智能指针,即使用户手动 reset() ,引用计数也不会降为 1,因为connections_ 中还有副本。
code 19 line 9 所调用的就是用户提供的回调函数,使用智能指针没问题,使用裸指针就可能出问题。
// code 20
// 正确的回调
void EchoServer::onConnection(const muduo::net::TcpConnectionPtr& conn) {
LOG_INFO << "EchoServer - " << conn->peerAddress().toIpPort() << " -> "
<< conn->localAddress().toIpPort() << " is "
<< (conn->connected() ? "UP" : "DOWN");
}
// 错误的回调
void EchoServer::onConnection(muduo::net::TcpConnection* conn) {
delete conn;
}
另外一个可能导致指针悬空的情景是在多线程中,服务器关闭时 TcpServer::~TcpServer() 开始把所有 TcpConnection 对象都删除,如果其他线程还在使用这个TcpConnection对象,会直接崩溃。更具体一点,如果其他线程正在处理 TcpConnection 的发送消息任务,至少要等它发送完再释放内存。这里就涉及到了 TcpConnection 的析构。
无论是主动断开连接,还是被动断开连接,通过回调最终都会到达 TcpServer::removeConnection(),然后是 TcpServer::removeConnectionInLoop(),在其中会将 conn 从 connections_ 里移除,移除之后该 TcpConnectionPtr 对象就只有当下唯一份了。之后通过 std::bind 其生命周期得到了暂时的延长,由于在 TcpConnection::connectDestroyed()中没有发生拷贝,那么退出函数作用域之后,该 TcpConnectionPtr 对象的引用计数减为 0,堆上分配的内存空间也会被删除。
// code 21
void TcpServer::removeConnection(const TcpConnectionPtr& conn) {
// FIXME: unsafe
loop_->runInLoop(std::bind(&TcpServer::removeConnectionInLoop, this, conn));
}
void TcpServer::removeConnectionInLoop(const TcpConnectionPtr& conn) {
...
size_t n = connections_.erase(conn->name());
(void)n;
assert(n == 1);
EventLoop* ioLoop = conn->getLoop();
ioLoop->queueInLoop(
std::bind(&TcpConnection::connectDestroyed, conn));
}
void TcpConnection::connectDestroyed() {
loop_->assertInLoopThread();
if (state_ == kConnected)
{
setState(kDisconnected);
channel_->disableAll();
connectionCallback_(shared_from_this());
}
channel_->remove();
}
TcpServer::~TcpServer() 中TcpConnection对象生命周期的追踪也不复杂,可以自己看一下,也可以参考 [4]。
与智能指针相关的还有最后一个问题,如果 TcpConnection 中有正在发送的数据,怎么保证在触发 TcpConnection 断开机制后,能先让 TcpConnection 先把数据发送完再释放?接着 code 19 line 6,进入 tie() 函数。Channel 中的 tie_ 成员是一个 weakptr,用来观察其指向的 shared_ptr 是否存在。当有事件到达后,会触发 Channel::handleEvent() 函数,如果可以通过 `tie.lock()成功提升为 shared_ptr,那么说明其观察的对象还存在,可以后续的操作,同时由于将提升后的指针保存在了guard中,可以保证TcpConnectionPtr对象的引用计数无论如何都减少不到 0,即使之前提到的析构流程全部结束。等到事件处理完之后,退出函数作用域,该TcpConnectionPtr` 对象的引用计数才能减为 0。
// code 22
std::weak_ptr<void> tie_;
void Channel::tie(const std::shared_ptr<void>& obj) {
tie_ = obj;
tied_ = true;
}
void Channel::handleEvent(Timestamp receiveTime) {
std::shared_ptr<void> guard;
if (tied_) {
guard = tie_.lock();
if (guard) {
handleEventWithGuard(receiveTime);
}
} else {
handleEventWithGuard(receiveTime);
}
}
3.2 Buffer 的设计与实现
虽然这一小节的标题叫做设计与实现,但是我不想涉及过多的具体内容,因为 Buffer 的设计在 [2] 中已经讲的非常详细了,其实现体现在代码中基本上就是一对一的翻译过程。本节主要是想展示一些设计思想上的内容。
首先是为什么要有 Buffer?为什么不能直接接收和发送呢,如果直接使用 read()、write() 系统调用进行操作,就可以直接将应用层数据发送出去或者将内核数据读取到应用层,加上 Buffer 以后,相当于在应用层数据和内核缓冲区之间又多了一层,会不会造成负面影响呢?[2] 中明确,应用层的缓冲区是必要的,因为非阻塞 IO 的核心就是避免阻塞以在 read() 和 write() 为代表的系统调用上。
对于发送来说,假设应用程序需要发送 40KB 数据,但是操作系统的 TCP 发送缓冲区只有 25KB 剩余空间,如果等待内核缓冲区可用,就会阻塞当前线程,因为不知道对方什么时候收到并读取数据。因此网络库应该把这 15KB 数据先缓存起来,等 fd 变得可写的时候立刻发送数据,这样操作才不会造成阻塞。需要注意,如果应用程序随后又要发送 50KB 数据,而此时发送缓冲区中尚有未发送的数据,那么网络库应该将这 50KB 数据追加到发送缓冲区的末尾,而不能立刻尝试 write(),因为这样有可能打乱数据的顺序。对于接收来说,假设一次读到的数据不够一个完整的数据包,那么这些已经读到的数据应该先暂存在某个地方,等剩余的数据收到之后再一并处理。所以说,发送缓冲区和接收缓冲区的存在都是必要的。
Buffer 在代码上有一个值得剖析的地方,就是 Buffer::readFd()。根据分析,在读取数据时,我们希望一次性读取完毕,落到实现上,就是要准备一个大的缓冲区。但是同时还要尽可能减少内存占用,因为如果有 10000 个并发连接,每个连接一建立就分配各 50KB 的读写缓冲区的话,将占用1GB 内存。muduo 用 readv() 结合栈上空间巧妙地解决了这个问题。
具体做法是,在栈上准备一个 65536 字节的 extrabuf,然后利用 readv() 来取数据,iovec 有两块,第一块指向 Buffer 中的 writable 字节,另一块指栈上的 extrabuf。这样如果读入的数据不多,那么全部都读到 Buffer 中去了。如果长度超过 Buffer 的 writable 字节数,就会读到上的 extrabuf 里,然后程序再将 extrabuf 里的数据 append() 到 Buffer 中。这么做利用了临时栈上空间,避免每个连接的初始 Buffer 过大造成的内存浪费,也避免反复调用 read() 的系统开销。
// code 23
ssize_t Buffer::readFd(int fd, int* savedErrno) {
// saved an ioctl()/FIONREAD call to tell how much to read
char extrabuf[65536];
struct iovec vec[2];
const size_t writable = writableBytes();
vec[0].iov_base = begin()+writerIndex_;
vec[0].iov_len = writable;
vec[1].iov_base = extrabuf;
vec[1].iov_len = sizeof extrabuf;
// when there is enough space in this buffer, don't read into extrabuf.
// when extrabuf is used, we read 128k-1 bytes at most.
const int iovcnt = (writable < sizeof extrabuf) ? 2 : 1;
const ssize_t n = sockets::readv(fd, vec, iovcnt);
if (n < 0) {
*savedErrno = errno;
} else if (implicit_cast<size_t>(n) <= writable) {
writerIndex_ += n;
} else {
writerIndex_ = buffer_.size();
append(extrabuf, n - writable);
}
// if (n == writable + sizeof extrabuf)
// {
// goto line_30;
// }
return n;
}
因为 Buffer 算是一个单独的组件,参照 [2] 的相关章节和源码理解起来不难,这里就不再多说(主要是写到这写不动了)。
四、muduo 设计思想
在看书的过程中,有一些我认为非常重要,能给我启发的地方需要记录,但是整合在前面几部分会导致文章割裂感比较强,影响思路,不记录估计过几天就忘了,所以统一放在了这一部分。
4.1 ET 还是 LT?
非阻塞网络编程应该采用 ET 还是 LT?答案是 muduo、libuv、redis 等都是采用 LT 模式,下面简单分析一下。本小节部分参考 [https://zhuanlan.zhihu.com/p/562682496]。
首先是高低电平的理解。对于可读事件,内核中 socket 的 recv_buff 为空,是低电平,不空,是高电平。对于可写事件,内核中 socket 的 send_buff 为满 ,是低电平,不满,是高电平。简而言之,低电平状态下不能进行读、写操作,高电平则可以读、写。
LT 模式是在高电平时触发。连接建立后,只要读缓冲区有数据,就会一直触发可读事件,所以 LT 模式下,处理读事件时可以只读一次,后续读事件还会被触发,不用担心数据漏读。但是只要连接一建立,可写事件就会被触发(刚开始写缓冲区肯定为空),但是服务端又没有可以发送的数据,这会造成 CPU 资源的浪费(busy loop),所以 LT 模式下,只有需要写数据的时候才注册写事件,等到写完立刻将写事件注销掉。
ET 模式是低电平到高电平时触发。读事件只有在数据到来时被触发一次,所以 ET 模式下,读事件要一次性处理完,否则会造成数据漏读。写事件可以在一开始注册,此时不会被触发,需要发送数据时直接发送即可,但是要注意如果一次性写不完,缓冲区就会变成低电平,要重新注册写事件,等到内核将缓冲区数据发出,从低电平变为高电平,会再次触发写事件,发送剩余的数据。
最后是 muduo 为什么选择 LT 模式?一是 LT 模式编程更容易,并且不会出现漏掉事件的 bug,也不会漏读数据。二是对于 LT 模式,如果可以将数据一次性读取完,那么就和 ET 相同,也只会触发一次读事件,另外LT 模式下一次性读取完数据只会调用一次 read(),而 ET 模式至少需要两次,因为 ET 模式下 read() 必须返回 EAGAIN 才可以。写数据的情景也类似。三是在文件描述符较少的情况下,epoll 不一定比 poll 高效,使用 LT 可以于 poll 兼容,必要的时候可以切换为 PollPoller。
[2] 提出理想的做法是读事件采用 LT 模式,写事件采用 ET 模式,但是 Linux 不支持(不清楚现在有没有支持)。
4.2 muduo 的性能如何?
在 [2] 中展示了 muduo 与其他网络库性能方面的对比,这里简单记录一下。
首先是与 Boost.asio、libevent2 在吞吐量方面的对比,使用的测试方法是 ping pong 协议。在 ping pong 消息为 16KB 时,muduo 比 libevent2 快 70%,原因是 libevent2 每次只能从 socket 读取 4096 字节的数据,而 muduo 是一次性读完的,系统调用的性价比更高。当 ping pong 消息改为 4096 字节后,两者吞吐量就比较接近了。
接着是与 libevent2 在事件处理效率上的对比,使用的测试方法是击鼓传花场景。两者性能接近。但是有个小问题,muduo 花在初始化上的时间要更长,原因是 muduo 在更新已有的 fd 时使用的是 epoll_ctl(fd, EPOLL_CTL_MOD, ...),而 libevent2 使用的是 epoll_ctl(fd, EPOLL_CTL_ADD, ...) 进行重复添加,然后忽略错误。在这种操作逻辑下,修改比重复添加要耗时,这是内核的原因。
4.3 muduo 网络库的一些特点
这小节是非常零散的记录,有 [2] 中的摘抄,还有自己的一些想法,没什么逻辑也不严谨,可以跳过。
muduo 是最早使用 C++ 11 特性的项目之一,除去网络编程之外,关于现代 C++ 的实践也值得学习。muduo 使用设置回调的形式订制自己的 TCP 网络服务,另一种方式是继承并且重写基类。
muduo 中大部分类都是不可拷贝的,如 EventLoop、Channel、Poller、Timer、Acceptor、TcpServer。
EventLoop 对象的生命周期和其所属的线程一样长,它不必是 heap 对象。muduo 中的部分成员函数只能在 IO 线程调用,所以用 isInLoopThread() 和 assertInLoopThread() 等函数进行检查和断言。
Channel 对象始终只会属于一个 EventLoop,属于一个 IO 线程。Channel 会持有一个 fd,但它并不拥有这个 fd,也就是在析构的的时候不会负责关闭该 fd。Channel 的生命周期由 TcpConnection 负责。Channel 的成员函数都只能在 IO 线程调用,因此更新数据成员不必加锁。
Poller 是 EventLoop 的间接成员,EventLoop 通过 unique_ptr 持有,只供其所属的 EventLoop 在 IO 线程调用,因此无需加锁,其生命周期与 EventLoop 相等。
TimerQueue 同样是只会在所属的 IO 线程调用,所以也是不用加锁。TimerQueue 的构造函数中会将 timerfdChannel_ 的读事件注册到其所属的 EventLoop 的 Poller 中。
我们可以通过 EventLoop::quit() 手动终止事件循环,但是不是立即生效的,而是当前循环结束后,在 while() 循环条件里判断之后退出的。
runInLoop() 配合 queueInLoop() 实现了跨线程的函数转移调用,这涉及了函数参数的跨线程转移,最简单的实现就是将数据拷贝一份,绝对安全但是会有性能损失。queueInLoop() 有两种情况会唤醒 IO 线程,一是调用 queueInLoop() 的线程不是 IO 线程,二是调用 queueInLoop() 的线程是 IO 线程,但是此时位于 doPendingFunctors() 中。
Acceptor 接受新连接使用了最近但的一次接受一个连接的方式,还有循环接受连接直到没有新连接,或者每次接受 N 个连接,后两种策略是为短链接服务准备的,而 muduo 的目标是为长连接服务。
Buffer 底层以 std::vector 作为容器,是一块连续的可以自动扩容的内存,对外表现出 queue 的特性。Buffer 不是线程安全的,Buffer 是属于 TcpConnection 的,需要保证 TcpConnection 在自己所属的线程执行。
sendInLoop() 和 handleWrite() 都只调用了一次 write() 而不会反复调用直至它返回 EAGAIN,是因为如果第一次 write() 没有能够发送完数据的话,第二次调用几乎肯定会返回 EAGAIN。
TCP No Delay 和 TCP keepalive 都是常用的 TCP 选项,前者用来禁用 Nagle 算法,避免连续发包出现延迟,这对于编写低延迟的网络服务很重要。后者是定期探查 TCP 连接是否还存在。
epoll 在并发连接数较大而活动连接比不高的时候,比 poll 高效。
面试问题
项目基础
1.简单介绍⼀下你的项目
高性能分布式服务器网络框架
这个项⽬是我在学习计算机⽹络和Linux socket编程过程中写的,基于C++11实现了高性能分布式服务器网络框架。用来将分布式服务部署到不同服务器节点,为客户端提供远程服务调用的框架。具体要点如下:
- 使用 C++11 重写并简化 muduo 网络库;
重写muduo网络库,使用C++11语法去除了Boost库的依赖。采用了基于采用OOP思想,Reactor方式,one loop peer thead 的模式,驱动的事件回调的epoll + 线程池面向对象,通过多线程和事件循环机制实现高并发处理。服务器的⽹络模型是主从reactor加线程池的模式,IO处理使⽤了⾮阻塞IO和IO多路复⽤技术。项⽬中的⼯作可以分为两部分,⼀部分是服务器⽹络框架、⽇志系统等⼀些基本系统的搭建,另⼀部分是为了提⾼服务器性能所做的⼀些优化,⽐如内存池等⼀些额外系统的搭建。最后还对系统中的部分功能进⾏了功能和压⼒测试。
- 仿写了 tcmalloc 的高并发内存池;
实现了高效的多线程内存管理,使用基于页面的内存分配机制,用于替换系统的内存分配相关函数malloc 和 free。使用三层Cache结构,Thread Cache: 主要解决锁竞争的问题;Central Cache: 主要负责居中调度的问题;Page Cache: 主要负责提供以页为单位的大块内存;解决外部碎片的问题,同时也尽可能的减少内部碎片的产生。使用三层基数树用来对页面和Span间的映射。
使用 protobuf 来进行 RPC 序列化/反序列化,同时使用来实现RPC框架;
使用 Zookeeper 来作为分布式的注册和发现服务;
2.项⽬中的难点?
项⽬中我主要的⼯作可以分为两部分:
⼀部分是服务器⽹络框架、⽇志系统等⼀些基本系统的搭建,这部分的难点主要就是技术的理解和选型,以及将⼀些开源的框架调整后应⽤到我的项⽬中去。
另⼀部分是为了提⾼服务器性能所做的⼀些优化,⽐如内存池等⼀些额外系统的搭建。
3.项⽬中遇到的困难?是如何解决的?
⼀⽅⾯是对不同的技术理解不够深刻,难以选出最合适的技术框架。这部分的话我主要是反复阅读作者在GitHub提供的⼀些技术⽂档,同时也去搜索⼀些技术对⽐的⽂章去看,如果没有任何相关的资料我会尝试去联系作者。
另⼀⽅⾯是编程期间遇到的困难,在代码编写的过程中由于⼯程能⼒不⾜,程序总会出现⼀些bug。这部分的话我⾸先是通过⽇志或者gdb去定位bug,然后推断bug出现的原因并尝试修复,如果是⾃⼰⽬前⽔平⽆法修复的bug,我会先到⽹上去查找有没有同类型问题的解决⽅法,然后向同学或者直接到StackOverflow等⼀些国外知名论坛上求助。
4.针对项⽬做了哪些优化?
1.程序本身
减少程序等待 IO 的事件:⾮阻塞 IO + IO 多路复⽤
设计⾼性能⽹络框架,同步 IO(主从 reactor + 线程池)和异步 IO(proactor)
【减少系统调⽤】避免频繁申请/释放内存:线程池、内存池
【减少系统调⽤】对于⽂件发送,使⽤零拷⻉函数 sendFile() 来发送,避免拷⻉数据到⽤户态
【减少系统调⽤】尽量减少锁的使⽤,如果需要,尽量减⼩临界区(⽇志系统和线程池)
TODO
5.项⽬中⽤到哪些设计模式?
单例模式:在线程池、内存池中都有使⽤到。
单例模式可以分为懒汉式和饿汉式,两者之间的区别在于创建实例的时间不同:
懒汉式:指系统运⾏中,实例并不存在,只有当需要使⽤该实例时,才会去创建并使⽤实例。(这种⽅式要考虑线程安全)
饿汉式:指系统⼀运⾏,就初始化创建实例,当需要时,直接调⽤即可。(本身就线程安全,没有多线程的问题)
6.C++ ⾯向对象特性在项⽬中的体现
c++⾯向对象特性有封装、继承、多态。
⾸先是封装,我在项⽬中将各个模块使⽤类进⾏封装,⽐如连接⽤ Tcpconnection 类来封装,⽇志就⽤ log 类来封装,将类的属性私有化,⽐如请求的解析态,并且对外的接⼝设置为公有,⽐如连接的重置,不对外暴露⾃身的私有⽅法,⽐如读写的回调函数等。还有⼀个就是,项⽬中每个模块都使⽤了各⾃的命名空间进⾏封装,避免了命名冲突或者名字污染。
然后是继承,项⽬中的继承⽤得⽐较少,主要是对⼯具类的继承,项⽬中多个地⽅使⽤到 noncopyable 和enable_shared_from_this,保证了代码的复⽤性。实际上对共有功能可以设计⼀个基类来继承。
最后是多态。
7.你从这个项⽬中学到了什么,或者说有什么收获
8.很多⼈的简历上都会有这个项⽬,为什么你还要选择?
项⽬是在学习计⽹的过程中逐步搭建的,这个项⽬综合性⽐较强,从中既能学习Linux环境下的⼀些系统调⽤,也能熟悉⽹络编程和⼀些⽹络框架,其中也根据⾃⼰的理解加⼊了⼀些性能调优的⼿段。
9.为了减少系统调⽤,你具体做了哪些⼯作?
(分类讲:线程池、内存池、缓存机制;零拷⻉)
10.说⼀下你这个WebServer的整体运⾏流程,优点是什么?
I/O任务和计算任务解耦,避免计算密集型连接占⽤subReactor导致⽆法响应其他连接,可扩展性好
11.QPS测试以及测试工具
项⽬细节
1.线程池
1.1 你的线程池⼯作线程处理完⼀个任务后的状态是什么?
1.2 讲⼀下你项⽬中线程池的作⽤?具体是怎么实现的?有参考开源的线程池实现吗?
1.3 请你实现⼀个简单的线程池(现场⼿撕)
C++实现的简易线程池,包含线程数量,启动标志位,线程列表以及条件变量。构造函数主要是声明未启动和线程数量的。start函数为启动线程池,将num个线程绑定threadfunc⾃定义函数并执⾏,加⼊线程列表stop是暂时停⽌线程,并由条件变量通知所有线程。析构函数是停⽌,阻塞所有线程并将其从线程列表剔除后删除,清空线程列表。
//待完成
1.4 项⽬的中线程池是怎么搭建的,⼤概讲⼀下原理?
2.⽇志系统
- 【蔚来⼀⾯】异步⽇志系统是怎么实现异步的?业务线程的写⼊是怎么同步的?(加锁),回去了解⼀下⽆锁队列
- 【蔚来⼆⾯】如果服务器在运⾏的过程中,实际存储的⽂件被其他⽤户修改了,会发⽣什么?(这部分没考虑到。。。)有什么优化的想法吗?(想法⼀(被否决):定时和实际⽂件对⽐;想法⼆(被否决):进程修改后通知缓存;想法三:类似于内存⻚⾯的换⼊换出,每次从cache读⼊时,先判断实际⽂件去对⽐,可以对⽐最后修改时间或者通过摘要算法判断)
- 【经纬恒润⼀⾯】为什么要做⽇志系统?讲⼀下⽇志系统的双缓冲?异步和同步的区别?
- 【经纬恒润⼆⾯】⽇志系统的异步体现在什么地⽅?与同步的区别?为什么设计成双缓冲⽽不⽤更多的缓冲区?(前端缓冲不⾜时会⾃动扩展,但是双缓冲⾜够应付使⽤场景,因为⽇志只记录必要的信息,并不会太多)
- 【地平线⼆⾯】讲⼀下你的⽇志系统的怎么做的(balabala)?异步指的是什么?异步和同步的区别?如果服务器崩溃的话,你的⽇志系统会发⽣什么?(未写⼊⽂件的所有⽇志都会丢失,但是会有时间戳)这个问题应该怎么解决?(想了好久也没什么好的想法,最后扯了点。。。如果是进程crash的话,可以使⽤⼀个⽇志进程来写⼊⽇志;如果是主机宕机的话可以考虑分布式⽇志,将⽇志分发到不同的主机上写⼊)
3.内存池
讲⼀讲为什么要加⼊内存池?项⽬中所有的内存申请都⾛内存池吗?
【oppo⼀⾯】连接对象和缓存对象都⾛内存池,这⾥挖坑了相⽐于 new 的性能提升在哪?(避免了系统调⽤的开销), new 的系统调⽤开销有多少?(纳秒级),可以忽略吗?(不能,在⾼并发场景下,越往后的连接延迟越明显)new 的主要开销在哪?(系统调⽤和构造函数)new ⼀定会陷⼊内核态吗?(不⼀定,因为底层是 malloc , malloc 根据分配内存的⼤⼩不同有两种分配⽅式,⼩于128k使⽤ brk() ,⼤于 128k 使⽤ mmap() )代码随想录知识星球那你内存池对于⼩内存的申请相⽐ new 还有优势吗?(到这⾥才明⽩⾯试官挖的坑,赶紧sorrymaker,考虑不周),但是对于缓存的对象是有必要⾛内存池的,下去再好好理⼀理。(学到了)
4.并发性问题
如果同时1000个客户端进⾏访问请求,线程数不多,怎么能及时响应处理每⼀个呢?
⾸先这种问法就相当于问服务器如何处理⾼并发的问题。⾸先我项⽬中使⽤了I/O多路复⽤技术,每个线程中管理⼀定数量的连接,只有线程池中的连接有请求,epoll就会返回请求的连接列表,管理该连接的线程获取活动列表,然后依次处理各个连接的请求。如果该线程没有任务,就会等待主reactor分配任务。这样就能达到服务器⾼并发的要求,同⼀时刻,每个线程都在处理⾃⼰所管理连接的请求。
如果⼀个客户请求需要占⽤线程很久的时间,会不会影响接下来的客户请求呢,有什么好的策略呢?
影响分析
会影响这个⼤请求的所在线程的所有请求,因为每个eventLoop都是依次处理它通过epoll获得的活动事件,也就是活动连接。如果该eventloop处理的连接占⽤时间过⻓的话,该线程后续的请求只能在请求队列中等待被处理,从⽽影响接下来的客户请求。
应对策略
主 reactor 的⻆度:可以记录⼀下每个从reactor的阻塞连接数,主reactor根据每个reactor的当前负载来分发请求,达到负载均衡的效果。
从 reactor 的⻆度:
超时时间:为每个连接分配⼀个时间⽚,类似于操作系统的进程调度,当当前连接的时间⽚⽤完以后,将其重新加⼊请求队列,响应其他连接的请求,进⼀步来说,还可以为每个连接设置⼀个优先级,这样可以优先响应重要的连接,有点像 HTTP/2 的优先级。
关闭时间:为了避免部分连接⻓时间占⽤服务器资源,可以给每个连接设置⼀个最⼤响应时间,当⼀个连接的最⼤响应时间⽤完后,服务器可以主动将这个连接断开,让其重新连接。
相似的问题
- 【荣耀⼆⾯】如果⼀个连接请求耗时⾮常⻓,会发⽣什么情况?(反问是IO耗时,还是计算耗时?如果是IO
耗时的话,则会阻塞同⼀subreactor中的所有线程,如何是计算耗时的话,因为本身也设计了计算线程池,
对服务器本身并没有太多影响)
- 【荣耀⼆⾯】如果⼀个连接请求的资源⾮常⼤,在发送响应报⽂时会造成响应其他连接的请求吗?有什么优化
的⽅法?(断点续传,设置响应报⽂的⼤⼩上限,当响应报⽂超出上限时,可以记录已经发送的位置,之后可
以选择继续由该线程进⾏发送,也可以转交给其他线程进⾏发送)
5.IO多路复⽤
1.说⼀下什么是ET,什么是LT,有什么区别?
LT:⽔平触发模式,只要内核缓冲区有数据就⼀直通知,只要socket处于可读状态或可写状态,就会⼀直返回sockfd;是默认的⼯作模式,⽀持阻塞IO和⾮阻塞IO
ET:边沿触发模式,只有状态发⽣变化才通知并且这个状态只会通知⼀次,只有当socket由不可写到可写或由不可读到可读,才会返回其sockfd;只⽀持⾮阻塞IO
2.LT什么时候会触发?ET呢?
LT模式
- 对于读操作
只要内核读缓冲区不为空,LT模式返回读就绪。
- 对于写操作
只要内核写缓冲区还不满,LT模式会返回写就绪。
ET模式
- 对于读操作
当缓冲区由不可读变为可读的时候,即缓冲区由空变为不空的时候。
当有新数据到达时,即缓冲区中的待读数据变多的时候。
当缓冲区有数据可读,且应⽤进程对相应的描述符进⾏EPOLL_CTL_MOD 修改EPOLLIN事件时。
- 对于写操作
当缓冲区由不可写变为可写时。
当有旧数据被发送⾛,即缓冲区中的内容变少的时候。
当缓冲区有空间可写,且应⽤进程对相应的描述符进⾏EPOLL_CTL_MOD 修改EPOLLOUT事件时。
3.为什么ET模式不可以⽂件描述符阻塞,⽽LT模式可以呢?
因为ET模式是当fd有可读事件时,epoll_wait()只会通知⼀次,如果没有⼀次把数据读完,那么要到下⼀次fd有可读事件epoll才会通知。⽽且在ET模式下,在触发可读事件后,需要循环读取信息,直到把数据读完。如果把这个fd设置成阻塞,数据读完以后read()就阻塞在那了。⽆法进⾏后续请求的处理。LT模式不需要每次读完数据,只要有数据可读,epoll_wait()就会⼀直通知。所以 LT模式下去读的话,内核缓冲区肯定是有数据可以读的,不会造成没有数据读⽽阻塞的情况。
4.你⽤了epoll,说⼀下为什么⽤epoll,还有其他多路复⽤⽅式吗?区别是什么?
⽂件描述符集合的存储位置
对于 select 和 poll 来说,所有⽂件描述符都是在⽤户态被加⼊其⽂件描述符集合的,每次调⽤都需要将整个集合拷⻉到内核态;epoll 则将整个⽂件描述符集合维护在内核态,每次添加⽂件描述符的时候都需要执⾏⼀个系统调⽤。系统调⽤的开销是很⼤的,⽽且在有很多短期活跃连接的情况下,由于这些⼤量的系统调⽤开销,epoll 可能会慢于 select 和 poll。
⽂件描述符集合的表示⽅法
select 使⽤线性表描述⽂件描述符集合,⽂件描述符有上限;poll使⽤链表来描述;epoll底层通过红⿊树来描述,并且维护⼀个就绪列表,将事件表中已经就绪的事件添加到这⾥,在使⽤epoll_wait调⽤时,仅观察这个list中有没有数据即可。
遍历⽅式
select 和 poll 的最⼤开销来⾃内核判断是否有⽂件描述符就绪这⼀过程:每次执⾏ select 或 poll 调⽤时,它们会采⽤遍历的⽅式,遍历整个⽂件描述符集合去判断各个⽂件描述符是否有活动;epoll 则不需要去以这种⽅式检查,当有活动产⽣时,会⾃动触发 epoll 回调函数通知epoll⽂件描述符,然后内核将这些就绪的⽂件描述符放到就绪列表中等待epoll_wait调⽤后被处理。
触发模式
select和poll都只能⼯作在相对低效的LT模式下,⽽epoll同时⽀持LT和ET模式。
适⽤场景
当监测的fd数量较⼩,且各个fd都很活跃的情况下,建议使⽤select和poll;当监听的fd数量较多,且单位时间仅部分fd活跃的情况下,使⽤epoll会明显提升性能。
5.【远景智能三⾯】io多路复⽤是同步还是异步?同步io和异步io有什么区别?为什么在项⽬中不⽤异步io?
(linux本身提供的asio⽬前只⽀持⽂件fd,不⽀持⽹络fd,但是可以⽤⼀个线程去模拟异步io的操作)
6.并发模型
1.reactor、proactor模型的区别?
Reactor 是⾮阻塞同步⽹络模式,感知的是就绪可读写事件。在每次感知到有事件发⽣(⽐如可读就绪事件)后,就需要应⽤进程主动调⽤ read ⽅法来完成数据的读取,也就是要应⽤进程主动将 socket 接收缓存中的数据读到应⽤进程内存中,这个过程是同步的,读取完数据后应⽤进程才能处理数据。
Proactor 是异步⽹络模式, 感知的是已完成的读写事件。在发起异步读写请求时,需要传⼊数据缓冲区的地址(⽤来存放结果数据)等信息,这样系统内核才可以⾃动帮我们把数据的读写⼯作完成,这⾥的读写⼯作全程由操作系统来做,并不需要像 Reactor 那样还需要应⽤进程主动发起 read/write 来读写数据,操作系统完成读写⼯作后,就会通知应⽤进程直接处理数据。
2.Proactor这么好⽤,那你为什么不⽤?
在 Linux 下的异步 I/O 是不完善的, aio 系列函数是由 POSIX 定义的异步操作接⼝,不是真正的操作系统级别⽀持的,⽽是在⽤户空间模拟出来的异步,并且仅仅⽀持基于本地⽂件的 aio 异步操作,⽹络编程中的 socket 是不⽀持的,也有考虑过使⽤模拟的proactor模式来开发,但是这样需要浪费⼀个线程专⻔负责 IO 的处理。⽽ Windows ⾥实现了⼀套完整的⽀持 socket 的异步编程接⼝,这套接⼝就是 IOCP ,是由操作系统级别实现的异步 I/O,真正意义上异步 I/O,因此在 Windows ⾥实现⾼性能⽹络程序可以使⽤效率更⾼的 Proactor ⽅案。代码随想录知识星球reactor模式中,各个模式的区别?Reactor模型是⼀个针对同步I/O的⽹络模型,主要是使⽤⼀个reactor负责监听和分配事件,将I/O事件分派给对应的Handler。新的事件包含连接建⽴就绪、读就绪、写就绪等。reactor模型中⼜可以细分为单reactor单线程、单reactor多线程、以及主从reactor模式。
单reactor单线程模型就是使⽤ I/O 多路复⽤技术,当其获取到活动的事件列表时,就在reactor中进⾏读取请求、业务处理、返回响应,这样的好处是整个模型都使⽤⼀个线程,不存在资源的争夺问题。但是如果⼀个事件的业务处理太过耗时,会导致后续所有的事件都得不到处理。
单reactor多线程就是⽤于解决这个问题,这个模型中reactor中只负责数据的接收和发送,reactor将业务处理分给线程池中的线程进⾏处理,完成后将数据返回给reactor进⾏发送,避免了在reactor进⾏业务处理,但是 IO 操作都在reactor中进⾏,容易存在性能问题。⽽且因为是多线程,线程池中每个线程完成业务后都需要将结果传递给reactor进⾏发送,还会涉及到共享数据的互斥和保护机制。
主从reactor就是将reactor分为主reactor和从reactor,主reactor中只负责连接的建⽴和分配,读取请求、业务处理、返回响应等耗时的操作均在从reactor中处理,能够有效地应对⾼并发的场合。subreactor负责读写数据,由线程池进⾏业务处理
【中兴⼀⾯】讲⼀下项⽬中的⽹络框架?为什么要采⽤这个框架?有了解其他的⽅案吗?为什么不采⽤?
【经纬恒润⼀⾯】为什么选择主从reactor+线程池的模式(将IO操作和业务处理解耦)?epoll配合什么IO使⽤?简单介绍下epoll?了解proactor吗,讲⼀下区别?
【荣耀⼆⾯】介绍⼀下项⽬中的⽹络框架?为什么选择这个⽹络框架?
4.跳表 skiplist
【中兴⼀⾯】讲⼀下跳表的原理?使⽤场景?如何保证查询效率?(通过概率近似保证当前层的索引数是上⼀层的⼀半)
【远景智能三⾯】存储引擎的定时写⼊是怎么实现的?每次都将内存中的所有数据写⼊⽂件,没有改变的数据是否会重复写⼊?(会,可以通过在⽂件写⼊实际操作来避免)那实际操作在系统中会出现相互抵消的情况,如何优化?(开⼀个后台线程,定时合并实际操作,并将实际操作应⽤到⽂件中)
【联想⼆⾯】介绍⼀下你web服务器的存储引擎,为什么要做这么⼀个存储引擎?(学习数据库的时候接触到了,⽐较感兴趣所以模仿做了⼀下)讲⼀下跳表的原理,查找是怎么做的(从顶层节点开始找,⽅式类似于⼆分查找),插⼊节点的过程是怎么样的(先将节点插⼊最底层,然后为了保证保证查找效率,上⼀层的节点数需要近似为下⼀层的1/2,因此通过随机数的⽅式模拟这个概率,如果是偶数则在当前层记录节点,否则继续进⼊下⼀层),删除节点呢(从最底层往上层去删除即可)B+树了解吗,说⼀下B+树的底层实现,说⼀下B+树和跳表的区别?
测试问题
【华为⼀⾯】在开发过程中有进⾏过测试吗?(做了单元测试、集成测试、功能测试、压⼒测试)压⼒测试是
怎么做的?(分⽹络框架、⽇志系统)
【联想⼀⾯】在做这个项⽬的过程中做了哪些测试,发现了什么问题?有针对遇到的问题去做优化吗?(主要
讲了下⽇志系统的并发性问题)