2-美团太平洋系统
实习
0.自我介绍
面试官您好,我是来自电子科技大学计算机科学与工程学院计算机技术专业 的25届毕业生李兴杰。我有一段美团后端开发的3个月实习经历,我的技术栈主要是C++,在实习阶段接触了一些Java后端开发的基础,也对Java有一定的了解。在本科和读研期间,我也积极参加了很多计算机视觉、数据挖掘以及数学建模相关的竞赛,获得了一些国家级和省部级奖项。我的兴趣爱好是健身和游泳,我对我自己评价是性格比较随和,对自己感兴趣的领域比较执着,善于学习新的技术,有比较好的学习能力。
1.整体业务
我们部门是做B端的业务,架构比较复杂。整体的业务是 做的 叫太平洋系统,为美团客服服务。我们做的是其中的一个核心业务,工单系统。工单就像一个问题追踪器,通过用户打电话、在线进线,客服会为用户的问题反馈,建立工单,通过工单可以能够清晰地进行问题追踪、处理和归档,标准化服务的根据过程。
1 实习做的事
1.负责工单系统中对外RPC接口的编写,如工单扩展字段、数据对象等功能的CRUD接口。
2.负责做一些线上问题的修复,如NPE,监控埋点覆盖等。
3.负责一些小工具的开发。如工单侧数据对象换绑查询工具等。
4.完成工单侧架构梳理,工单建单流程等文档梳理
5.独立完成工单系统扩展字段变更统计需求的设计文档、代码编写、单测和上线。
实习收获:熟悉了JAVA后端开发上线流程,掌握了从设计文档到部署的各个环节。了解美团工单业务需求,能够根据需求进 行高效的代码编写和优化。
2.工单业务
工单系统主要分为配置台和运行时,配置台是提供一些功能或者页面配置,可以动态配置工单问题、按钮、页面、工单流程、状态等,是运营侧在管理。运行时是客服使用,根据配置台的配置,动态建立工单、进行工单的流转和处理。
业务流程主要是客服接听电话或者在线坐席在线接收到用户反馈,客服会根据反馈的问题先給一个初步的一二级分类,如用户问题,外卖问题,这两级问题也成为一二级FAQ。客服可以通过这两级问题进入一个弹屏页面,通过搜索手机号获取订单信息。客服可以通过搜索配置台配置的工单类型,选择对应的具体问题对应的工单类型。工单类型下绑定了一个具体的六级FAQ问题,比如外卖超时等问题,并且在配置台配置了相应的工单的创建页以及详情页面,还有工单的流程配置信息等,流程配置是工单的状态机,需要以怎样的流程驱动工单直至结案。流程通过流程节点定义,节点就是工单的实时状态,比如一线处理中,申请赔付中,已结案等。客服可以通过配置的按钮和动作进行一些节点的流转,最终将工单结案。
3.数据流
数据对象:在工单页面中,数据流是通过统一的防腐层来管理,叫做数据对象,数据对象是太平洋系统承载信息的载体,与真实的业务数据映射。可以通过配置台配置,在创建工单时,通过数据对象记录和展示业务信息。数据对象其实实质上就是定义的一个RPC获取真实业务数据的工具。
扩展字段:在建立工单时,会有一些配置的扩展字段,扩展字段是由一些前端页面组件组成,承载不同工单的业务数据。比如一些表单,备注信息等,主要是携带工单创建的一些业务信息,供后续业务逻辑使用。
4.做的需求 - 工单扩展字段变更统计
在工单系统中,每个工单可以关联一个或多个扩展字段,这些字段包括文本框、选择器、表格等特定组件。在工单处理过程中,扩展字段可能会随着工单的流转发生变更,需要自动统计指定字段在指定时间的变更次数及其变更前后的内容。我独立完成了这个需求的设计文档、代码编写、单测和上线。
技术栈:Spring Boot、Mybatis、Squirrel(Redis)、Mafka(Kafka)、Cerberus
- 配置台:
- 允许增删指定的统计字段,统计字段的ID保存在缓存中以便快速查询。
- 通过数据订阅统计字段表的Binlog,并使用Mafka生产者发送Binlog消息。
- 在另一个服务中消费消息并存入缓存,实现数据库与缓存的同步。
- 运行态:
- 通过定时任务自动统计变更记录,提供详细变更查询接口。可以根据日期、字段名称或ID查询对应字段的变更次数。
- 订阅工单字段表的Binlog,通过Mafka消费Binlog消息统计变更内容,通过缓存快速判断是否为需要统计的字段。
- 使用Cerberus解决统计字段变更记录并发安全问题。根据字段ID和日期作为key,锁住对应的行记录,完成字段变更的统计。
需求项目收获:了解了真实业务需求和代码规范问题。更加了解了数据一致性问题,以及MQ以及分布式锁的使用场景。
3-分布式KV缓存系统
1.项目介绍
项目介绍:一个分布式的基于内存的 K-V 存储系统,基于 CS 架构,可灵活部署多个分布式服务器节点,为客户端提供增删查改操作,并支持单一节点故障迁移功能。由一个中心路由节点与多个slave存储节点成。
1.中心节点具有客户端路由,服务节点哈希环注册,故障监听迁移,LRU高频数据缓存等功能,为客户端提供服务。
2.每个存储节点使用单线程,使用跳表实现数据存储,包含自己的数据与上一个节点备份数据。
3.支持单一节点故障数据迁移,中心节点监听故障并通知存储节点故障迁移。
4.灵活增删节点,允许动态增删存储节点,实现了存储节点优雅停机与自动迁移
5.存储节点通过阻塞队列,使用一个异步线程进行主从同步。
6.服务器通信网络库:重写并简化 muduo 网络库。采用了Reactor模型,one loop peer thead 的模式。通过 epoll +线程池,使用多线程和事件循环机制实现高并发网络库。
项目背景: 之前在学习分布式和缓存以及redis的时候,尝试想着使用另外一种方式实现一下。同时锻炼自己的编码能力以及对加深分布式缓存、跳表、一致性哈希、以及底层网络库的认识。
项目收获:熟悉了 muduo网络库的底层实现原理以及网络编程;加深了对跳表、一致性哈希以及分布式KV 缓存的理解。
2.中心路由节点
- 客户端请求的节点,请求数据会映射到哈希环中,中心节点会进行完成数据的查询,返回给客户端。
- 中心节点还起到监听集群状态和数据迁移的作用。通过定时(10)秒对各个slave节点发送通知,如果超过3次未收到回应就会被认定为主观下线,从哈希环上移除注册节点,这段时间内的数据操作会直接打到备份节点中。每一个节点的上一个节点也同时与此节点建立心跳,当上一个节点维持的心跳也消失的时候,会被主观下线,中心节点同时完成数据迁移的工作。
- 中心节点本地会通过LRU记录缓存一些高频访问数据,用于快速返回,而无需查找slave节点。
3.slave存储节点
slave节点在建立连接时会注册到中心节点的哈希环上,并与中心节点维持一个长连接。
通过跳表实现的基于内存的分布式 K-V 缓存系统(为什么用跳表实现?原因是方便对数据进行哈希范围查询方便迁移数据)
slave存储节点命令使用的单线程的处理模式,避免因多线程问题导致访问跳表出现线程安全问题。
slave节点会分为两个跳表,一个用来存储自己的数据,一个用来存储上一个节点的备份数据。
4.单一节点故障节点数据迁移
通过心跳机制检测节点情况,中心节点维持心跳机制,若重复3次没有收到心跳,则主观会认为该节点挂掉,移除哈希环数据。当前一个节点与它的心跳消失时,回给中心节点发送请求,标记为客观下线。同时会进行数据迁移。而在这期间打到该slave节点的请求都会被中心节点路由到他的备份节点。从而对备份节点执行相应操作。
如果重复3次没有收到心跳,则认为该slave节点已经挂掉。则从中心节点将其移除,执行数据的迁移操作。而在数据迁移过程中的打进来的请求会被路由到备份节点中。

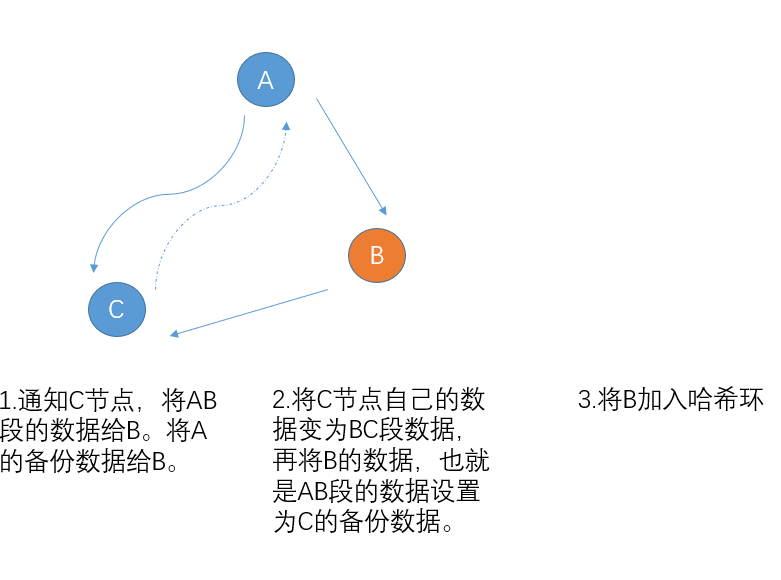
5.动态新增slave节点
slave节点新增首先会向中心节点发送连接请求。连接成功后,会进行节点间的数据自动迁移。数据迁移完成后,中心节点会将slave节点的数据以及连接注册到哈希环中。
6.分布式缓存的一致性问题
因为采用的是哈希环映射架构,一致性问题只会在节点与备份节点中存在,只需在缓存时同时操作节点与备份节点的数据。并通过判断是否同时操作成功来保证数据一致性。
操作不成功的原因主要有两个:网络延迟、服务器挂掉。
主从同步使用异步的日志复制来解决主从同步问题,当主节点接收到消息,会与从节点建立连接,将接收到的日志复制给备份节点。
7.优雅停机
采用特定的Stop命令,发送给中心节点,中心节点会注销哈希环上的节点数据,进行主动数据迁移
8.服务器通信网络库
Reactor 方式,one loop peer thead 的模式,驱动的事件回调的 epoll + 线程池面向对象,通过多线程和事件循环机制实现 高并发处理。
以EventLoop为核心的事件处理类
Channel:为了对关注的以及发生的读写事件和对应fd的封装。以及保存handler。
Poller:多路事件分发器的核心IO复用模块,使用epoll多路复用监听。通过poll函数监听活跃事件。返回活跃事件的Channel 列表。
EventLoop:事件循环处理类,调用poll函数,得到活跃事件。执行活跃事件对应的channel对应的handler方法。通过eventfd方式进行唤醒。同时执行异步队列里面的方法。
EventLoopThreadPool:基于EventLoop的线程池,保存固定数量的线程,每一个线程中会有一个EventLoop事件循环。
以TcpConnection为核心的连接类
Acceptor:主线程中用来监听新的连接的类,复制建立新的连接。建立连接后调用Callback函数,建立连接。
TcpConnection:在Acceptor建立监听之后,调用回调函数进行连接的建立。保存有对应的EventLoop,封装的Channel,为用户提供写入接口。
TcpServer:做线程配置,启动服务,建立连接的功能。其包含Acceptor以及多个TcpConnection连接还有一个主eventLoop。还有一个EventLoopThreadPool线程池。
启动流程:
- TcpServer 启动线程池(线程池会启动线程以及开启eventLoop事件监听),线程池处理的是读写回调。主线程对Acceptor开启监听,监听读事件,也就是新的连接。
- 当有新的连接来,会触发Acceptor的读事件新连接到来的回调,会通过轮询的方式,选择一个eventLoop,同时构造一个TcpConnection连接,设置读写回调函数。
- 通过调用TcpConnection的connectEstablished,在poller中注册新连接Channel读事件。
- 当有读事件发生,对应的eventLoop会对读事件进行处理。
- TcpConnection也提供对外了写的接口,在回调函数中,通过处理指定的信息,实现对客户端写入数据。
4-文本字符交易验证码识别算法
比赛项目介绍 : 使用已标记字符信息的实例字符验证码图像数据为训练样本(15000张),验证码中包含 噪声点、噪声线、重叠、形变等干扰。需基于提供的样本构建模型,对测试集中的字符验证码图像进行识别(15000张),提取有效的字符信息,使得能同时过滤多种干扰的验证码模型。最终通过计算识别精确度进行比赛排序。
主要工作
1.采用自动生成伪数据对模型进行预训练,使得更快拟合训练数据。
2.采用图像中值滤波,对图像进行降噪操作,去除椒盐噪声。并做一定的数据增强,如Rotate、Mix-up、Crop等。
3.采用半监督学习的策略进行样本学习,利用Fixmatch对图像进行强弱增强,有效利用无标签数据。采用Swin-transformer对模型进行训练。
4.训练策略采用CosLR策略 + Focal Loss损失。
5.最终识别精度98.87%,获2022数字中国创新大赛全国第三名(奖金2万元)。
Swin-transformer:
- 分层的注意力机制:Swin Transformer 采用了分层的注意力机制,允许有效地处理大规模图像数据。这种设计使得它在处理长序列输入时,计算复杂度不会显著增加,从而避免了耗时较长的问题。
- 跨层连接:Swin Transformer 引入了 CNN 的局部感知能力,同时保留了 Transformer 的自注意力机制。这种混合模型的设计使得 Swin Transformer 在多个视觉任务上表现出色。
OCR处理本身可以理解为转换序列的问题,使用tansformer更加契合当前任务。而使用SWin机制,采用分层注意力机制,更能捕获到局部特征关系。
Focal Loss:介绍,为什么用?
目的:解决分类问题中的类别不平衡问题。
原理:通过调整交叉熵损失函数,聚焦难以分类的样本。
动态缩放因子:用于降低易区分样本的权重,增加难分样本的损失比例。
整体流程和思路?
1.拿到数据之后要对数据进行分析,包括整体数字字符的数量分布。图片的大小分布,以及统计图片的均值方差等。
2.采用简单模型训练baseline,确定一下训练策略,如损失函数的定义,怎么预处理,图像降噪等。
3.以及是否需要其他策略,如半监督学习、对比学习等等。
4.通过确定训练策略,然后尝试更换backbone模型。
5.通过参数搜索调整,选择最佳参数训练模型。
比赛收获:这种打榜算法类比赛一般需要对数据的理解,然后通过分析数据,数据预处理,选择合适的模型,以及合适的训练策略,损失函数以及识别训练的一些trick提高分数。
为什么要转客户端?
游戏客户端:
1.我主要的开发技术栈市C++,游戏客户端更契合技术栈。
2.游戏客户端开发相对于后端开发能够有更多的开发正反馈,就是做了一款游戏能够展示出来,而不是向后端那样需要有个载体,可以提供更大的动力和信心去做好这件事。
3.我个人也经常玩游戏,对游戏还是很感兴趣,所以想参与到游戏开发中4
为什么实习选择美团而不是腾讯?
主要还是技术栈的因素,之前我认为这边做的c++后台,但是过来主要是做的java而且偏向与B端,业务复杂但是涉及到技术的比较少。还有一个原因是因为学校在成都这边,离学校比较近,导师那边有时候要求回去做什么事情。
个人未来职业规划
如果有幸加入咱们这边,首先,在前期因为没有接触过这方面的技术,首先要把基础的技术,用的工具等要掌握扎实,为未来的开发打下基础。
然后会在各个实际的开发项目中提升的技术,积累更多的开发经验,也要持续学习和了解新的技术。
最重要的是要培养自己的软技能,比如沟通能力、团队协作能力、问题解决能力。多思考,多总结。